why limu
提示
😄 略以下阅读,跳转至 👉🏼 常用 api
更快
limu让你像操作原生 js 对象一样操作不可变对象,提供一个回调函数让用户任意修改数据的副本,并以结构共享的方式,让引用变动只发生在产生数据变化的节点的途经路径上。
优化复制策略
区别于immer的写时复制机制,limu采用读时浅克隆写时标记修改机制,具体操作流程我们将以下图为例来讲解,使用produce接口生成草稿数据后,,limu只会用户读取草稿数据层的路径上完成相关节点的浅克隆
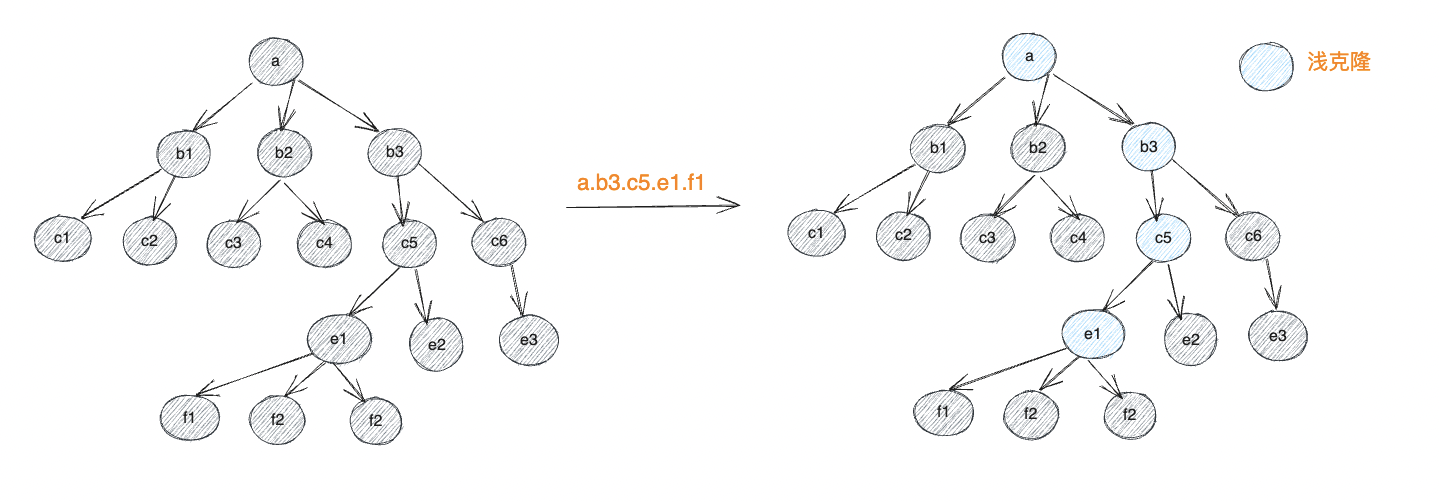
修改了目标节点下的值的时候,则会回溯该节点到跟节点的所有途径节点并标记这些节点为已修改 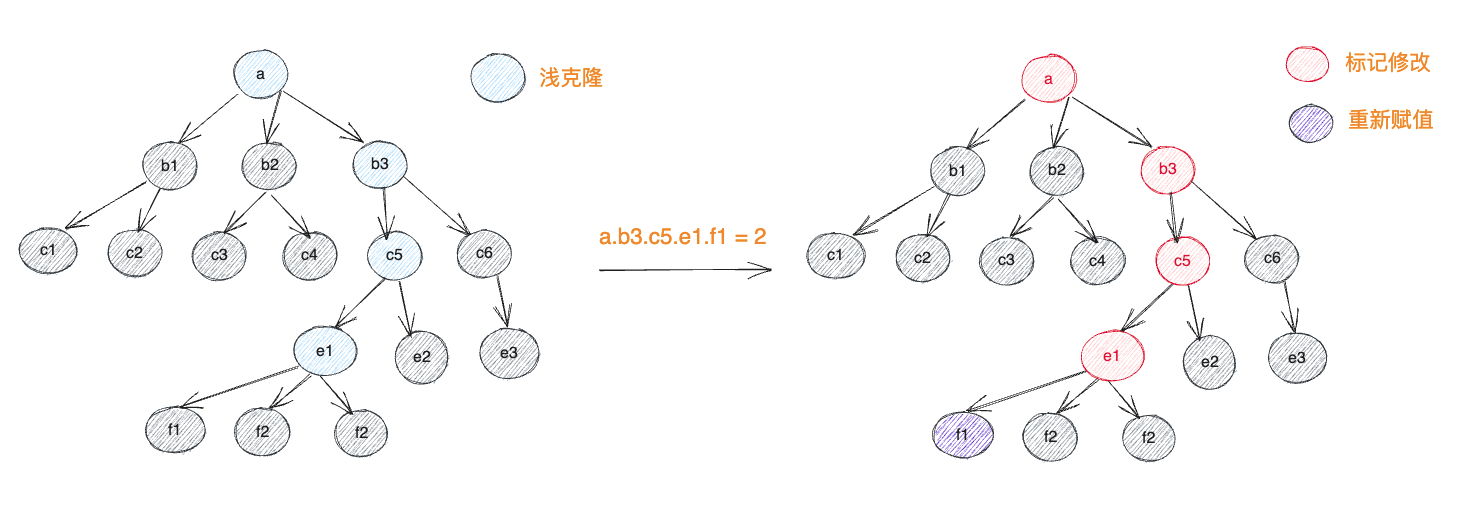
最后结束草稿生成final对象时,limu只需要从根节点把所有标记修改的节点的副本替换到对应位置即可,没有标记修改的节点则不使用副本(注:生成副本不代表已被修改)
这样的机制在对象的原始层级关系较为复杂且修改路径不广的场景下,且不需要冻结原始对象时,性能表现异常优异,可达到比 immer 快 5 倍或更多,只有在修改数据逐渐遍及整个对象所有节点时,limu的性能才会呈线性下载趋势,逐步接近immer,但也要比immer快很多。
性能测试
为了验证上述结论,用户可按照以下流程获得针对limu与immer性能测试对比数据
git clone https://github.com/tnfe/limu
cd limu
npm i
cd benchmark
npm i
node opBigData.js // 触发测试执行,控制台回显结果
# or
node caseReadWrite.js
我们准备两个用例,一个改编自 immer 官方的性能测试案例
执行 node opBigData.js 得到如下结果 
一个是我们自己准备的深层次 json 读写案例,结果如下

提示
可通过注入ST值调整不同的测试策略,例如 ST=1 node caseReadWrite.js,不注入时默认为 1
- ST=1,关闭冻结,不操作数组
- ST=2,关闭冻结,操作数组
- ST=3,开启冻结,不操作数组
- ST=4,开启冻结,操作数组